35 随机模拟
35.1 随机数
随机模拟是统计研究的重要方法, 另外许多现代统计计算方法(如MCMC)也是基于随机模拟的。 R中提供了多种不同概率分布的随机数函数, 可以批量地产生随机数。 一些R扩展包利用了随机模拟方法,如boot包进行bootstrap估计。
所谓随机数,实际是“伪随机数”, 是从一组起始值(称为种子), 按照某种递推算法向前递推得到的。 所以,从同一种子出发,得到的随机数序列是相同的。
为了得到可重现的结果, 随机模拟应该从固定不变的种子开始模拟。
用set.seed(k)指定一个编号为k的种子,
这样每次从编号k种子运行相同的模拟程序可以得到相同的结果。
还可以用set.seed()加选项kind=指定后续程序要使用的随机数发生器名称,
用normal.kind=指定要使用的正态分布随机数发生器名称。
R提供了多种分布的随机数函数,如runif(n)产生n个标准均匀分布随机数,
rnorm(n)产生n个标准正态分布随机数。
例如:
round(runif(5), 2)
## [1] 0.44 0.56 0.93 0.23 0.22
round(rnorm(5), 2)
## [1] -0.20 1.10 -0.02 0.16 2.02注意因为没有指定种子,每次运行会得到不同的结果。
在R命令行运行
可以查看R中提供的不同概率分布。
35.2 sample()函数
sample()函数从一个有限集合中无放回或有放回地随机抽取,
产生随机结果。
例如,为了设随机变量\(X\)取值于\(\{\text{正面}, \text{反面} \}\), 且\(P(X=\text{正面}) = 0.7 = 1 - P(X = \text{反面})\), 如下程序产生\(X\)的10个随机抽样值:
sample(c('正面', '反面'), size=10,
prob=c(0.7, 0.3), replace=TRUE)
## [1] "反面" "反面" "反面" "反面" "正面"
## [6] "正面" "正面" "正面" "反面" "反面"sample()的选项size指定抽样个数,
prob指定每个值的概率,
replace=TRUE说明是有放回抽样。
如果要做无放回等概率的随机抽样,
可以不指定prob和replace(缺省是FALSE)。
比如,下面的程序从1:10随机抽取4个:
如果要从\(1:n\)中等概率无放回随机抽样直到每一个都被抽过,只要用如:
这实际上返回了\(1:10\)的一个重排。
dplyr包的sample_n()函数与sample()类似,
但输入为数据框,
输出为随机抽取的数据框行子集。
35.3 随机模拟示例
35.3.1 估计期望值
设随机变量或随机向量\(X\)有复杂的分布, 使得期望\(\theta = E h(X)\)很难计算。 如果可以得到\(X\)的\(N\)个独立同分布抽样值\(X_1, X_2, \dots, X_N\), 则可估计\(\theta\)为: \[ \hat\theta = \frac{1}{N} \sum_{i=1}^N h(X_i) \] 这时\(E \hat\theta = \theta\), 估计无偏; 均方误差为 \[\begin{aligned} \text{MSE} =& E|\hat\theta - \theta|^2 = \text{Var}(\hat\theta) = \text{SE}^2 \\ =& \frac{\text{Var}(X)}{N} \approx \frac{S_N^2}{N} \end{aligned}\] 其中 \[ S_N^2 = \frac{1}{N-1} \sum_{i=1}^N (h(X_i) - \hat\theta)^2 \] 是样本方差。 由强大数律可知\(N\to\infty\)时\(\hat\theta\)依概率1收敛到\(\theta\), 由中心极限定理可知\(N\)充分大时\(\hat\theta\)有近似正态分布 \[ \text{N}(\theta, \text{SE}^2) . \]
例如,考虑正方形区域\(\Omega = \{(x,y): x \in [0,1], y \in [0,1] \}\), 以及其中的四分之一扇形\(A = \{(x,y): (x,y) \in \Omega, x^2 + y^2 \leq 1 \}\)。 设\(\boldsymbol X\)服从\(\Omega\)上的均匀分布, 令 \[ Y = \begin{cases} 1, & \text{当} \boldsymbol X \in A, \\ 0, & \text{其它} \end{cases} \] 则\(Y\)服从两点分布, 概率为 \[ p = E Y = \frac{\frac{1}{4} \pi 1^2}{1^2} = \frac{\pi}{4} \]
在\(\Omega\)中投入\(N=10000\)个点, 得到\(N\)个\(Y_i, i=1,2,\dots,N\)的值,估计\(\pi\)为 \[ \hat\pi = 4 \bar Y = \frac{4}{N} \sum_{i=1}^N Y_i \] \(E \hat\pi = \pi\), 估计的根均方误差可估计为 \[ \text{RMSE} = \sqrt{E | \hat\pi - \pi |^2} = 4 \frac{\sqrt{\text{Var}(Y)}}{\sqrt{N}} \approx 4 \frac{S_N}{\sqrt{N}} . \]
程序如下:
est_pi <- function(N){
set.seed(101)
x1 <- runif(N, 0, 1)
x2 <- runif(N, 0, 1)
y <- as.numeric(x1^2 + x2^2 <= 1)
hat_pi <- 4*mean(y)
se <- 4 * sd(y) / sqrt(N)
cat("N = ", N, " pi估计值 =", hat_pi, " SE =", se, "\n")
invisible(list(N=N, hat_pi = hat_pi, SE = se))
}
est_pi(1E4)
## N = 10000 pi估计值 = 3.14 SE = 0.01643372 估计的标准误差(SE)还是比较大, 提高到\(N=10^6\),精度可以增加一位小数:
35.3.2 线性回归模拟
考虑如下线性回归模型
\[\begin{aligned}
y = 10 + 2 x + \varepsilon,
\ \varepsilon \sim \text{N}(0, 0.5^2) .
\end{aligned}\]
假设有样本量\(n=10\)的一组样本, R函数lm()可以 可以得到截距\(a\),
斜率\(b\)的估计\(\hat a, \hat b\),
以及相应的标准误差\(\text{SE}(\hat a)\), \(\text{SE}(\hat b)\)。
样本可以模拟产生。
模型中的自变量\(x\)可以用随机数产生,
比如,用sample()函数从\(1:10\)中随机有放回地抽取\(n\)个。
模型中的随机误差项\(\varepsilon\)可以用rnorm()产生。
产生一组样本的程序如:
n <- 10; a <- 10; b <- 2
x <- sample(1:10, size=n, replace=TRUE)
eps <- rnorm(n, 0, 0.5)
y <- a + b * x + eps如下程序计算线性回归:
##
## Call:
## lm(formula = y ~ x)
##
## Coefficients:
## (Intercept) x
## 10.080 1.995如下程序计算线性回归的多种统计量:
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.76774 -0.14896 0.02445 0.33051 0.49779
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.08026 0.22313 45.18 6.37e-11 ***
## x 1.99518 0.04545 43.90 8.00e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4286 on 8 degrees of freedom
## Multiple R-squared: 0.9959, Adjusted R-squared: 0.9953
## F-statistic: 1927 on 1 and 8 DF, p-value: 8.004e-11如下程序返回一个矩阵, 包括\(a, b\)的估计值、标准误差、t检验统计量、检验p值:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.080258 0.22313107 45.17640 6.365149e-11
## x 1.995183 0.04545185 43.89664 8.003683e-11如下程序把上述矩阵的前两列拉直成一个向量返回:
## [1] 10.08025775 1.99518338 0.22313107 0.04545185这样得到 \(\hat a, \hat b, \text{SE}(\hat a), \text{SE}(\hat b)\)这四个值。
用replicate(, 复合语句)执行多次模拟, 返回向量或矩阵结果,
返回矩阵时,每列是一次模拟的结果。
下面是线性回归整个模拟程序,写成了一个函数。
reg.sim <- function(
a=10, b=2, sigma=0.5,
n=10, B=1000){
set.seed(1)
resm <- replicate(B, {
x <- sample(1:10, size=n, replace=TRUE)
eps <- rnorm(n, 0, 0.5)
y <- a + b * x + eps
c(summary(lm(y ~ x))$coefficients[,1:2])
})
resm <- t(resm)
colnames(resm) <- c('a', 'b', 'SE.a', 'SE.b')
cat(B, '次模拟的平均值:\n')
print( apply(resm, 2, mean) )
cat(B, '次模拟的标准差:\n')
print( apply(resm, 2, sd) )
}运行测试:
## 1000 次模拟的平均值:
## a b SE.a SE.b
## 9.9970476 1.9994490 0.3639505 0.0592510
## 1000 次模拟的标准差:
## a b SE.a SE.b
## 0.37974881 0.06297733 0.11992515 0.01795926可以看出,标准误差作为\(\hat a, \hat b\)的标准差估计, 与多次模拟得到多个\(\hat a, \hat b\)样本计算得到的标准差估计是比较接近的。 结果中\(\text{SE}(\hat a)\)的平均值为0.363, 1000次模拟的\(\hat a\)的样本标准差为0.393,比较接近; \(\text{SE}(\hat b)\)的平均值为0.0594, 1000次模拟的\(\hat b\)的样本标准差为0.0637,比较接近。
35.3.3 核密度的bootstrap置信区间
R自带的数据框faithful内保存了美国黄石国家公园Faithful火山的272次爆发持续时间和间歇时间。
为估计爆发持续时间的密度,可以用核密度估计方法,
R函数density可以执行此估计,
返回\(N\)个格子点上的密度曲线坐标:
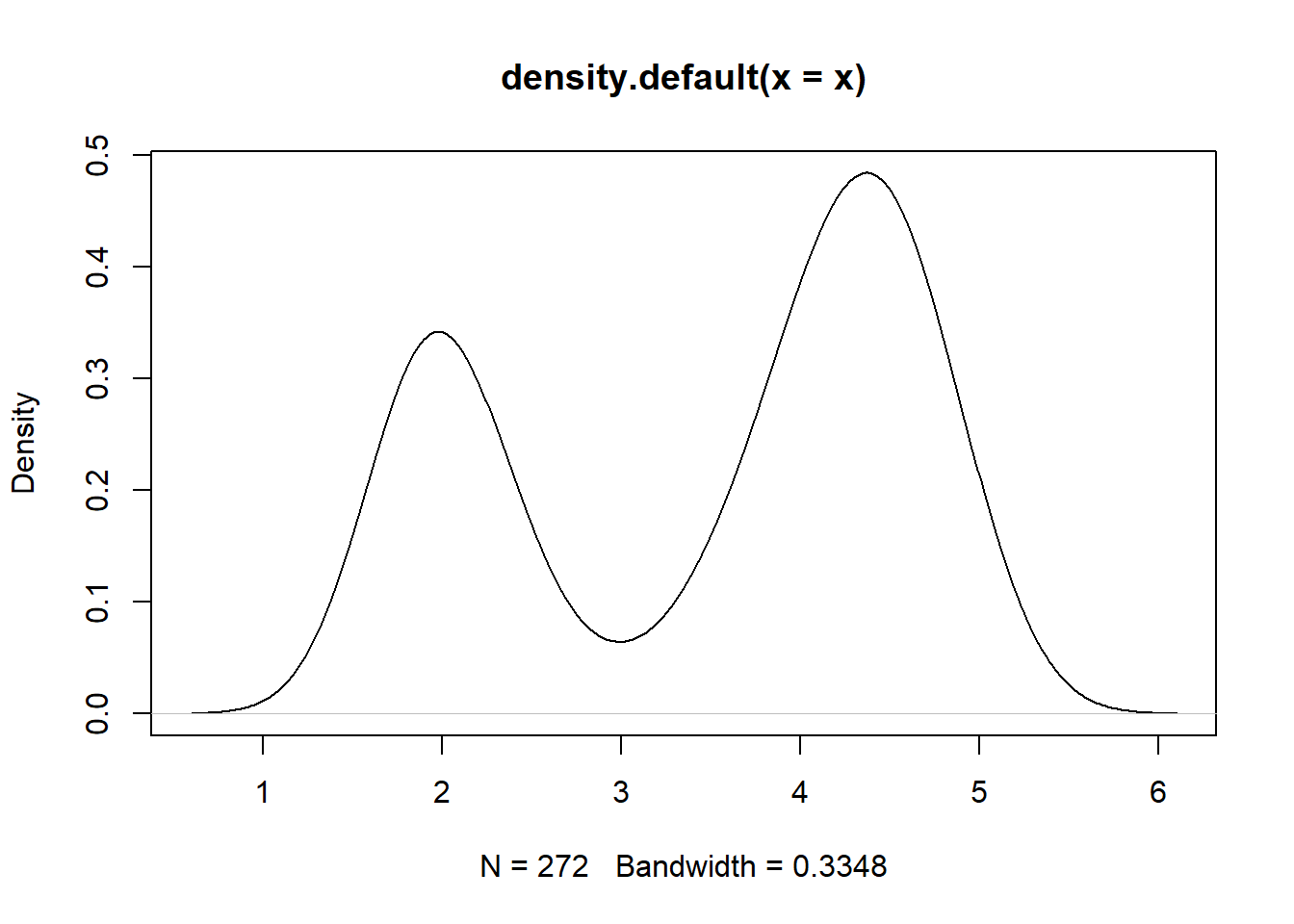
这个密度估计明显呈现出双峰形态。
核密度估计是统计估计, 为了得到其置信区间(给定每个\(x\)坐标,真实密度\(f(x)\)的单点的置信区间), 采用如下非参数bootstrap方法:
重复\(B=10000\)次, 每次从原始样本中有重复地抽取与原来大小相同的一组样本, 对这组样本计算核密度估计, 结果为\((x_i, y_i^{(j)}), i=1,2,\dots,N, j=1,2,\dots, B\), 每组样本估计\(N\)个格子点的密度曲线坐标, 横坐标不随样本改变。
对每个横坐标\(x_i\), 取bootstrap得到的\(B\)个\(y_i^{(j)}, j=1,2,\dots,B\)的0.025和0.975样本分位数, 作为真实密度\(f(x_i)\)的bootstrap置信区间。
在R中利用replicate()函数实现:
set.seed(1)
resm <- replicate(10000, {
x1 <- sample(x, replace=TRUE)
density(x1, from=min(est0$x),
to=max(est0$x))$y
})
CI <- apply(resm, 1, quantile, c(0.025, 0.975))
plot(est0, ylim=range(CI), type='n')
polygon(c(est0$x, rev(est0$x)),
c(CI[1,], rev(CI[2,])),
col='grey', border=FALSE)
lines(est0, lwd=2)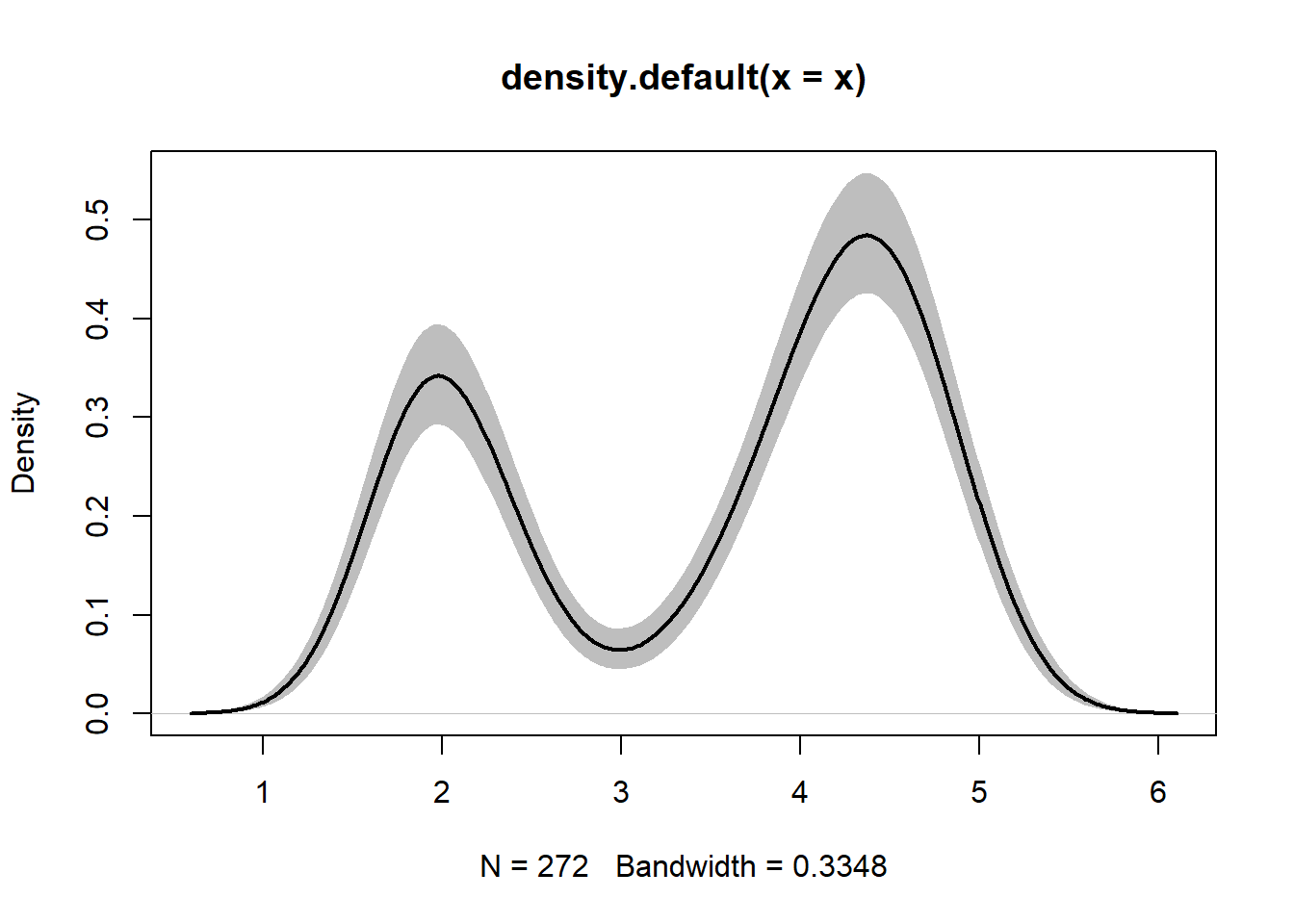
程序中用set.seed(1)保证每次运行得到的结果是不变的,
replicate()函数第一参数是重复模拟次数,
第二参数是复合语句,
这些语句是每次模拟要执行的计算。
在每次模拟中,
用带有replace=TRUE选项的sample()函数从样本中有放回地抽样得到一组bootstrap样本,
每次模拟的结果是在指定格子点上计算的核密度估计的纵坐标。
replicate()的结果为一个矩阵,
每一列是一次模拟得到的纵坐标集合。
对每个横坐标格子点,用quantile()函数计算\(B\)个bootstrap样本的2.5%和97.5%分位数,
循环用apply()函数表示。
polygon()函数指定一个多边形的顺序的顶点坐标用col=指定的颜色填充,
本程序中实现了置信下限与置信上限两条曲线之间的颜色填充。
lines()函数绘制了与原始样本对应的核密度估计曲线。